
快速入门
Python API
Prophet 遵循 sklearn 模型 API。我们创建一个 Prophet 类的实例,然后调用它的 fit 和 predict 方法。
Prophet 的输入始终是一个包含两列的数据帧:ds 和 y。ds(日期戳)列应为 Pandas 期望的格式,理想情况下,日期格式为 YYYY-MM-DD,时间戳格式为 YYYY-MM-DD HH:MM:SS。y 列必须是数字,表示我们希望预测的度量。
例如,让我们看一下关于 Peyton Manning 的维基百科页面的每日页面浏览量的对数时间序列。我们使用 R 中的 Wikipediatrend 包抓取了这些数据。Peyton Manning 提供了一个很好的例子,因为它说明了 Prophet 的一些功能,例如多重季节性、不断变化的增长率以及对特殊日子(例如 Manning 的季后赛和超级碗出场)进行建模的能力。该 CSV 文件可在此处 获得。
首先,我们将导入数据
1
2
3
4
# Python
import pandas as pd
from prophet import Prophet
1
2
3
4
# Python
df = pd.read_csv('https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_peyton_manning.csv')
df.head()
| ds | y | |
|---|---|---|
| 0 | 2007-12-10 | 9.590761 |
| 1 | 2007-12-11 | 8.519590 |
| 2 | 2007-12-12 | 8.183677 |
| 3 | 2007-12-13 | 8.072467 |
| 4 | 2007-12-14 | 7.893572 |
我们通过实例化一个新的 Prophet 对象来拟合模型。传递给构造函数的任何设置都将用于预测过程。然后,您调用它的 fit 方法并传入历史数据帧。拟合应该需要 1-5 秒。
1
2
3
4
# Python
m = Prophet()
m.fit(df)
然后,在包含要进行预测的日期(位于 ds 列中)的数据帧上进行预测。您可以使用辅助方法 Prophet.make_future_dataframe 获取一个合适的、可以扩展到未来指定天数的数据帧。默认情况下,它还将包括历史记录中的日期,因此我们将看到模型拟合。
1
2
3
4
# Python
future = m.make_future_dataframe(periods=365)
future.tail()
| ds | |
|---|---|
| 3265 | 2017-01-15 |
| 3266 | 2017-01-16 |
| 3267 | 2017-01-17 |
| 3268 | 2017-01-18 |
| 3269 | 2017-01-19 |
predict 方法将为 future 中的每一行分配一个预测值,并将其命名为 yhat。如果传入历史日期,它将提供一个样本内拟合。forecast 对象是一个新的数据帧,其中包含具有预测值的 yhat 列,以及组成部分和不确定性区间的列。
1
2
3
4
# Python
forecast = m.predict(future)
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()
| ds | yhat | yhat_lower | yhat_upper | |
|---|---|---|---|---|
| 3265 | 2017-01-15 | 8.212625 | 7.456310 | 8.959726 |
| 3266 | 2017-01-16 | 8.537635 | 7.842986 | 9.290934 |
| 3267 | 2017-01-17 | 8.325071 | 7.600879 | 9.072006 |
| 3268 | 2017-01-18 | 8.157723 | 7.512052 | 8.924022 |
| 3269 | 2017-01-19 | 8.169677 | 7.412473 | 8.946977 |
您可以通过调用 Prophet.plot 方法并传入您的预测数据帧来绘制预测。
1
2
3
# Python
fig1 = m.plot(forecast)

如果您想查看预测组成部分,可以使用 Prophet.plot_components 方法。默认情况下,您将看到时间序列的趋势、年度季节性和每周季节性。如果包含假日,您也会在此处看到它们。
1
2
3
# Python
fig2 = m.plot_components(forecast)
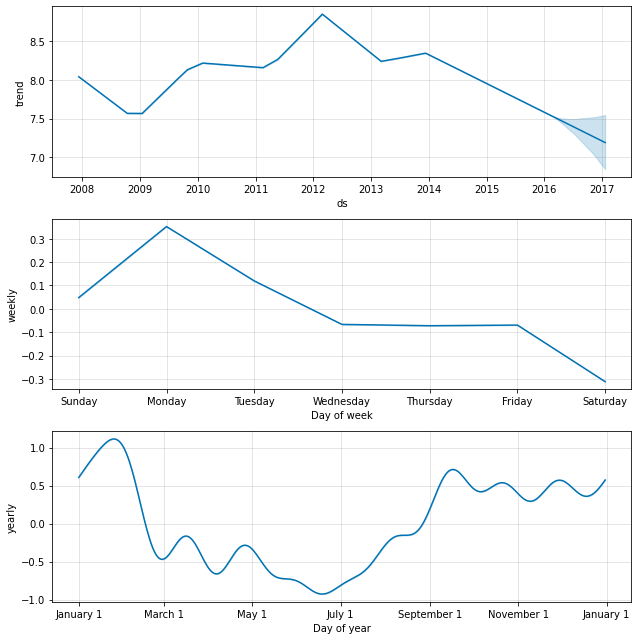
可以使用 plotly 创建预测和组成部分的交互式图形。您需要单独安装 plotly 4.0 或更高版本,因为它默认不会与 prophet 一起安装。您还需要安装 notebook 和 ipywidgets 包。
1
2
3
4
5
# Python
from prophet.plot import plot_plotly, plot_components_plotly
plot_plotly(m, forecast)
1
2
3
# Python
plot_components_plotly(m, forecast)
有关每种方法可用的选项的更多详细信息,请参见文档字符串,例如,通过 help(Prophet) 或 help(Prophet.fit)。
R API
在 R 中,我们使用常规模型拟合 API。我们提供了一个 prophet 函数,该函数执行拟合并返回一个模型对象。然后,您可以对此模型对象调用 predict 和 plot。
1
2
3
# R
library(prophet)
1
2
3
R[write to console]: Loading required package: Rcpp
R[write to console]: Loading required package: rlang
首先,我们读入数据并创建结果变量。与 Python API 中一样,这是一个包含 ds 和 y 列的数据帧,其中分别包含日期和数值。ds 列的日期格式应为 YYYY-MM-DD,时间戳格式应为 YYYY-MM-DD HH:MM:SS。与上述一样,此处我们使用 Peyton Manning 的维基百科页面的浏览量对数,可在此处 获得。
1
2
3
# R
df <- read.csv('https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_peyton_manning.csv')
我们调用 prophet 函数来拟合模型。第一个参数是历史数据帧。附加参数控制 Prophet 如何拟合数据,并在本文档后面的页面中进行了描述。
1
2
3
# R
m <- prophet(df)
在包含要进行预测的日期(位于 ds 列中)的数据帧上进行预测。make_future_dataframe 函数接受模型对象和要预测的周期数,并生成一个合适的数据帧。默认情况下,它还将包括历史日期,因此我们可以评估样本内拟合。
1
2
3
4
# R
future <- make_future_dataframe(m, periods = 365)
tail(future)
1
2
3
4
5
6
7
ds
3265 2017-01-14
3266 2017-01-15
3267 2017-01-16
3268 2017-01-17
3269 2017-01-18
3270 2017-01-19
与 R 中的大多数建模过程一样,我们使用泛型 predict 函数来获取我们的预测。forecast 对象是一个数据帧,其中包含包含预测值的 yhat 列。它具有用于不确定性区间和季节性组成部分的附加列。
1
2
3
4
# R
forecast <- predict(m, future)
tail(forecast[c('ds', 'yhat', 'yhat_lower', 'yhat_upper')])
1
2
3
4
5
6
7
ds yhat yhat_lower yhat_upper
3265 2017-01-14 7.818359 7.071228 8.550957
3266 2017-01-15 8.200125 7.475725 8.869495
3267 2017-01-16 8.525104 7.747071 9.226915
3268 2017-01-17 8.312482 7.551904 9.046774
3269 2017-01-18 8.145098 7.390770 8.863692
3270 2017-01-19 8.156964 7.381716 8.866507
您可以使用泛型 plot 函数来绘制预测,方法是传入模型和预测数据帧。
1
2
3
# R
plot(m, forecast)

您可以使用 prophet_plot_components 函数来查看分解为趋势、每周季节性和年度季节性的预测。
1
2
3
# R
prophet_plot_components(m, forecast)
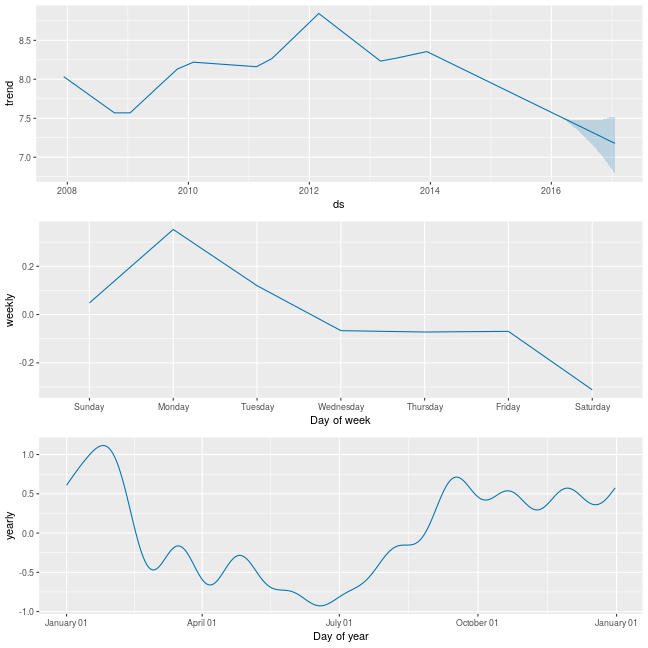
可以使用命令 dyplot.prophet(m, forecast) 使用 Dygraphs 创建预测的交互式图。
有关每种方法可用的选项的更多详细信息,请参见文档字符串,例如,通过 ?prophet 或 ?fit.prophet。该文档也可在 CRAN 上的 参考手册中找到。