
处理冲击
1
2
3
4
5
6
7
8
9
10
11
# Python
%matplotlib inline
from prophet import Prophet
import pandas as pd
from matplotlib import pyplot as plt
import logging
logging.getLogger('prophet').setLevel(logging.ERROR)
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['figure.figsize'] = 9, 6
由于 COVID-19 大流行导致的封锁,许多时间序列在 2020 年经历了“冲击”,例如媒体消费(Netflix、YouTube)、电子商务交易(亚马逊、eBay)的激增,而参加现场活动的人数急剧下降。
大多数这些时间序列也会在一段时间内保持其新水平,并受到封锁放松和/或疫苗驱动的波动的影响。
季节性模式也可能发生变化:例如,与 COVID 封锁之前相比,人们在工作日可能比周末消耗更少的媒体(总小时数),但在封锁期间,工作日消费可能更接近周末消费。
在本页中,我们将探讨一些使用 Prophet 功能捕获这些影响的策略
-
将因 COVID 事件引起的阶跃变化/峰值标记为一次性事件。
-
导致趋势和季节性变化的持续行为变化。
案例研究 - 行人活动
对于此案例研究,我们将使用墨尔本市的行人传感器数据。 此数据测量来自中央商务区各个位置的传感器的客流量,我们选择了一个传感器(Sensor_ID = 4)并将值聚合到每日粒度。
聚合数据集可以在 examples 文件夹中找到这里。
1
2
# Python
df = pd.read_csv('https://raw.githubusercontent.com/facebook/prophet/main/examples/example_pedestrians_covid.csv')
1
2
# Python
df.set_index('ds').plot();
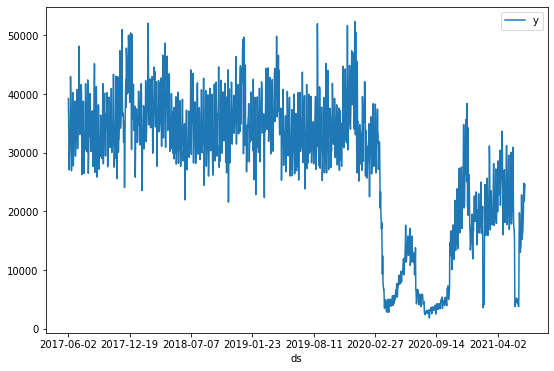
我们可以看到时间序列中的两个关键事件
-
2020 年 3 月 21 日左右客流量的最初下降,并在 2020 年 6 月 6 日左右开始恢复。这与世界卫生组织宣布大流行以及维多利亚州政府随后强制实施的封锁相对应。
-
经过一段时间的缓慢恢复后,2020 年 7 月 9 日左右客流量再次下降,并在 2020 年 10 月 27 日左右开始恢复。这与墨尔本都市区的“第二波”大流行相对应。
还有一些较短的严格封锁期导致时间序列突然下降:2021 年 2 月的 5 天和 2021 年 6 月初的 14 天。
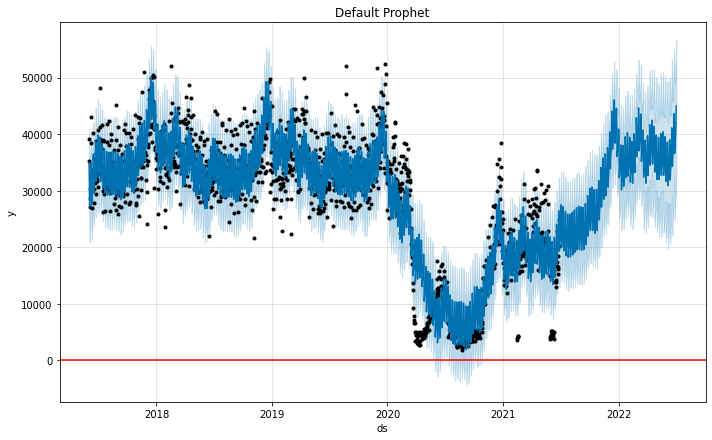
没有任何调整的默认模型
首先,我们将使用默认的 Prophet 设置拟合模型
1
2
3
4
5
# Python
m = Prophet()
m = m.fit(df)
future = m.make_future_dataframe(periods=366)
forecast = m.predict(future)
1
2
02:53:41 - cmdstanpy - INFO - Chain [1] start processing
02:53:41 - cmdstanpy - INFO - Chain [1] done processing
1
2
3
4
# Python
m.plot(forecast)
plt.axhline(y=0, color='red')
plt.title('Default Prophet');
1
2
# Python
m.plot_components(forecast);
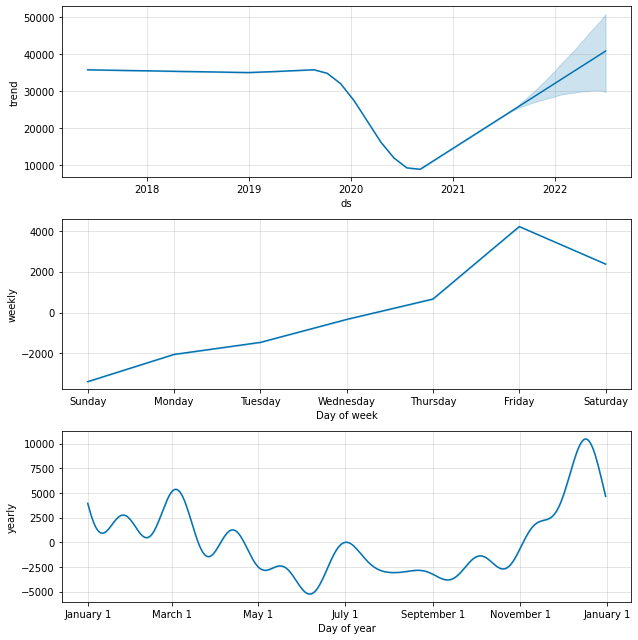
该模型似乎与过去的数据非常吻合,但请注意我们如何将下降和下降后的峰值作为趋势分量的一部分来捕获。
默认情况下,该模型假定这些大的峰值将来可能会出现,即使我们实际上不会在我们的预测范围内(在本例中为 1 年)看到相同数量级的峰值。 这导致对 2022 年客流量恢复的预测相当乐观。
将 COVID-19 封锁视为一次性假日
为了防止趋势分量捕获大的下降和峰值,我们可以将受 COVID-19 影响的日子视为将来不会再次发生的假日。 有关添加自定义假日的更多详细信息,请参见此处。 我们设置一个类似这样的 DataFrame 来描述受封锁影响的时期
1
2
3
4
5
6
7
8
9
10
11
# Python
lockdowns = pd.DataFrame([
{'holiday': 'lockdown_1', 'ds': '2020-03-21', 'lower_window': 0, 'ds_upper': '2020-06-06'},
{'holiday': 'lockdown_2', 'ds': '2020-07-09', 'lower_window': 0, 'ds_upper': '2020-10-27'},
{'holiday': 'lockdown_3', 'ds': '2021-02-13', 'lower_window': 0, 'ds_upper': '2021-02-17'},
{'holiday': 'lockdown_4', 'ds': '2021-05-28', 'lower_window': 0, 'ds_upper': '2021-06-10'},
])
for t_col in ['ds', 'ds_upper']:
lockdowns[t_col] = pd.to_datetime(lockdowns[t_col])
lockdowns['upper_window'] = (lockdowns['ds_upper'] - lockdowns['ds']).dt.days
lockdowns
| 假日 | ds | lower_window | ds_upper | upper_window | |
|---|---|---|---|---|---|
| 0 | lockdown_1 | 2020-03-21 | 0 | 2020-06-06 | 77 |
| 1 | lockdown_2 | 2020-07-09 | 0 | 2020-10-27 | 110 |
| 2 | lockdown_3 | 2021-02-13 | 0 | 2021-02-17 | 4 |
| 3 | lockdown_4 | 2021-05-28 | 0 | 2021-06-10 | 13 |
-
我们为每个封锁期都有一个条目,其中
ds指定封锁的开始。ds_upperProphet 不使用,但这是我们计算upper_window的便捷方式。 -
upper_window告诉 Prophet 封锁持续了封锁开始后的 x 天。 请注意,假日回归包含上限。
请注意,由于我们没有指定任何未来的日期,Prophet 会假定这些假日在创建未来的 dataframe 时不会再次发生(因此它们不会影响我们的预测)。 这与我们指定重复假日的方式不同。
1
2
3
4
5
# Python
m2 = Prophet(holidays=lockdowns)
m2 = m2.fit(df)
future2 = m2.make_future_dataframe(periods=366)
forecast2 = m2.predict(future2)
1
2
02:53:44 - cmdstanpy - INFO - Chain [1] start processing
02:53:45 - cmdstanpy - INFO - Chain [1] done processing
1
2
3
4
# Python
m2.plot(forecast2)
plt.axhline(y=0, color='red')
plt.title('Lockdowns as one-off holidays');
1
2
# Python
m2.plot_components(forecast2);
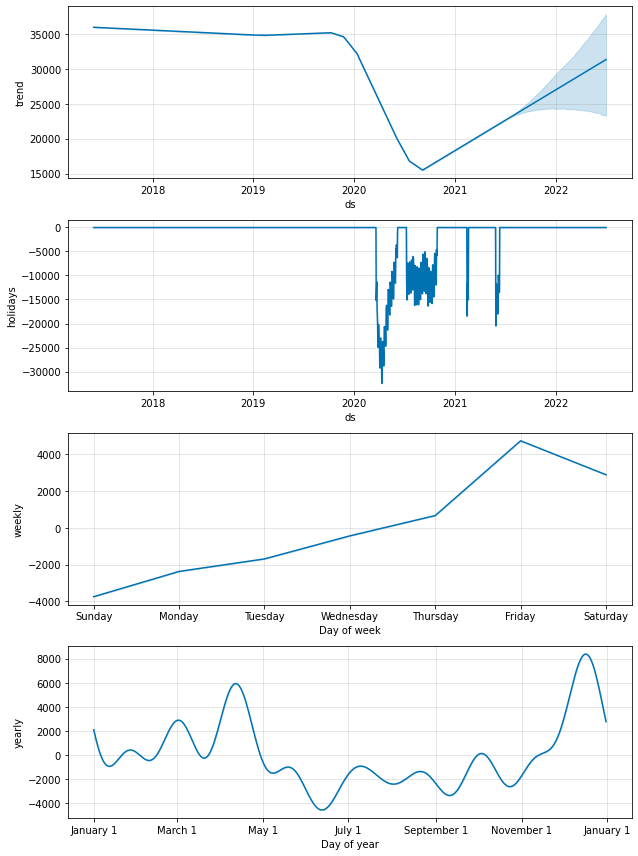
-
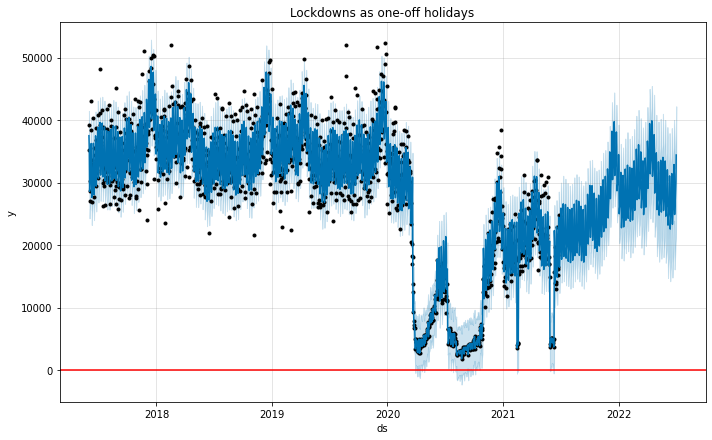
Prophet 正在明智地为封锁期内的日子分配较大的负面影响。
-
趋势的预测不是那么强烈/乐观,并且看起来相当合理。
感知检查趋势
在行为不断变化的环境中,重要的是确保模型的趋势分量能够捕获新兴模式,而不会过度拟合它们。
趋势变化点文档解释了我们可以调整趋势分量的两件事
-
变化点位置,默认情况下它们在历史记录的 80% 上均匀分布。 我们应该注意此范围的结束位置,并且如果我们认为最新的数据更好地反映了未来的行为,则扩展该范围(通过增加百分比或手动添加变化点)。
-
正则化的强度(
changepoint_prior_scale),它确定趋势的灵活性; 默认值为0.05,增加此值将使趋势更接近观察到的数据。
我们在下面绘制趋势分量和当前模型检测到的变化点。
1
2
3
4
# Python
from prophet.plot import add_changepoints_to_plot
fig = m2.plot(forecast2)
a = add_changepoints_to_plot(fig.gca(), m2, forecast2)
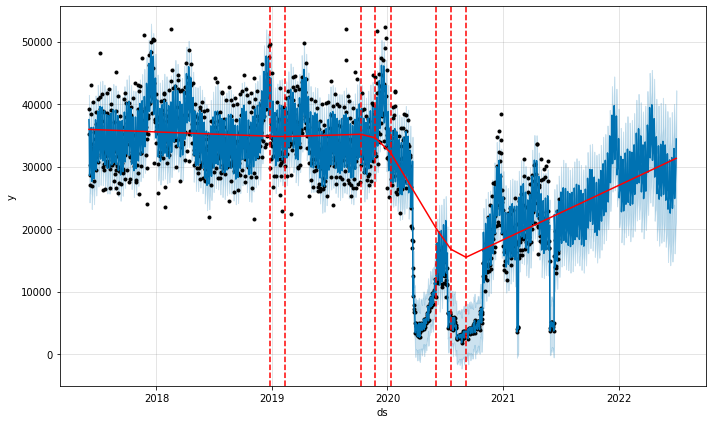
检测到的变化点看起来合理,并且未来的趋势跟踪了最新的活动上升趋势,但没有达到 2020 年底的程度。 这似乎适合对未来活动的最佳猜测。
我们可以看到如果我们想在模型训练中更多地强调 COVID 模式,预测会是什么样子; 我们可以通过在 2020 年之后添加更多潜在的变化点并使趋势更加灵活来实现此目的。
1
2
3
4
5
6
7
# Python
m3_changepoints = (
# 10 potential changepoints in 2.5 years
pd.date_range('2017-06-02', '2020-01-01', periods=10).date.tolist() +
# 15 potential changepoints in 1 year 2 months
pd.date_range('2020-02-01', '2021-04-01', periods=15).date.tolist()
)
1
2
3
4
5
# Python
# Default changepoint_prior_scale is 0.05, so 1.0 will lead to much more flexibility in comparison.
m3 = Prophet(holidays=lockdowns, changepoints=m3_changepoints, changepoint_prior_scale=1.0)
m3 = m3.fit(df)
forecast3 = m3.predict(future2)
1
2
02:53:49 - cmdstanpy - INFO - Chain [1] start processing
02:53:52 - cmdstanpy - INFO - Chain [1] done processing
1
2
3
4
# Python
from prophet.plot import add_changepoints_to_plot
fig = m3.plot(forecast3)
a = add_changepoints_to_plot(fig.gca(), m3, forecast3)
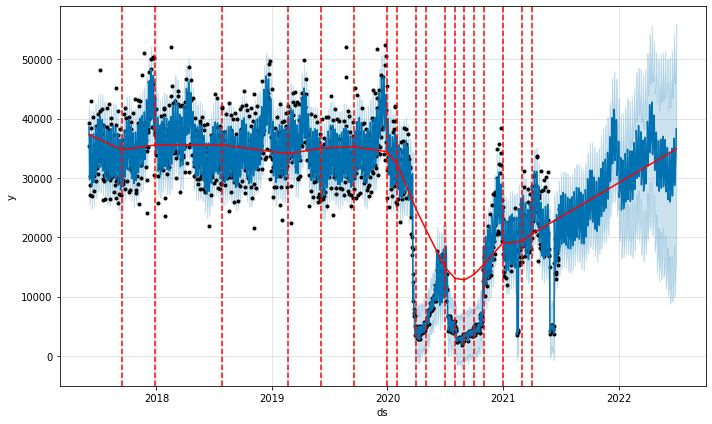
我们看到许多变化点是在 COVID 之后检测到的,这与放宽/收紧封锁的各种波动相匹配。 总的来说,趋势曲线和预测的趋势与我们之前的模型非常相似,但由于我们在历史记录中拾取的趋势变化数量较多,因此我们看到了更多的不确定性。
我们可能不会选择这个模型而不是具有默认参数的模型作为最佳估计,但这很好地证明了我们如何将我们对哪些模式重要的信念纳入模型中。
COVID 前后季节性的变化
前几节中的季节性分量图显示,与其他工作日相比,周五的活动高峰。 如果我们不确定这是否会在封锁后仍然成立,我们可以将条件季节性添加到模型中。 有关条件季节性的更多详细信息,请参见此处。
首先,我们在历史 dataframe 中定义布尔列以标记“covid 前”和“covid 后”时期
1
2
3
4
# Python
df2 = df.copy()
df2['pre_covid'] = pd.to_datetime(df2['ds']) < pd.to_datetime('2020-03-21')
df2['post_covid'] = ~df2['pre_covid']
我们有兴趣在此处建模的条件季节性是一周中的哪一天(“每周”)季节性。 为此,我们首先在创建 Prophet 模型时关闭默认的weekly_seasonality。
1
2
# Python
m4 = Prophet(holidays=lockdowns, weekly_seasonality=False)
然后,我们手动添加此每周季节性,作为两个不同的模型分量 - 一个用于 covid 前,一个用于 covid 后。 请注意,fourier_order=3是每周季节性的默认设置。 在此之后,我们可以运行.fit()。
1
2
3
4
5
6
7
8
9
10
11
12
13
# Python
m4.add_seasonality(
name='weekly_pre_covid',
period=7,
fourier_order=3,
condition_name='pre_covid',
)
m4.add_seasonality(
name='weekly_post_covid',
period=7,
fourier_order=3,
condition_name='post_covid',
);
1
2
# Python
m4 = m4.fit(df2)
1
2
02:53:55 - cmdstanpy - INFO - Chain [1] start processing
02:53:56 - cmdstanpy - INFO - Chain [1] done processing
我们还需要在未来的 dataframe 中创建pre_covid和post_covid标志。 这是为了 Prophet 可以将正确的每周季节性参数应用于每个未来日期。
1
2
3
4
# Python
future4 = m4.make_future_dataframe(periods=366)
future4['pre_covid'] = pd.to_datetime(future4['ds']) < pd.to_datetime('2020-03-21')
future4['post_covid'] = ~future4['pre_covid']
1
2
# Python
forecast4 = m4.predict(future4)
1
2
3
4
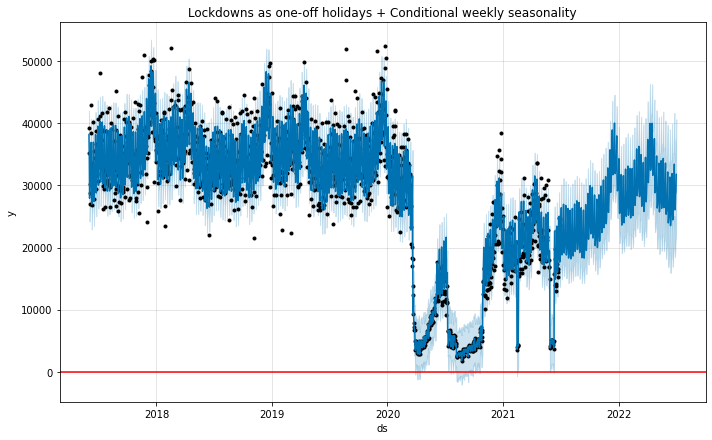
# Python
m4.plot(forecast4)
plt.axhline(y=0, color='red')
plt.title('Lockdowns as one-off holidays + Conditional weekly seasonality');
1
2
# Python
m4.plot_components(forecast4);
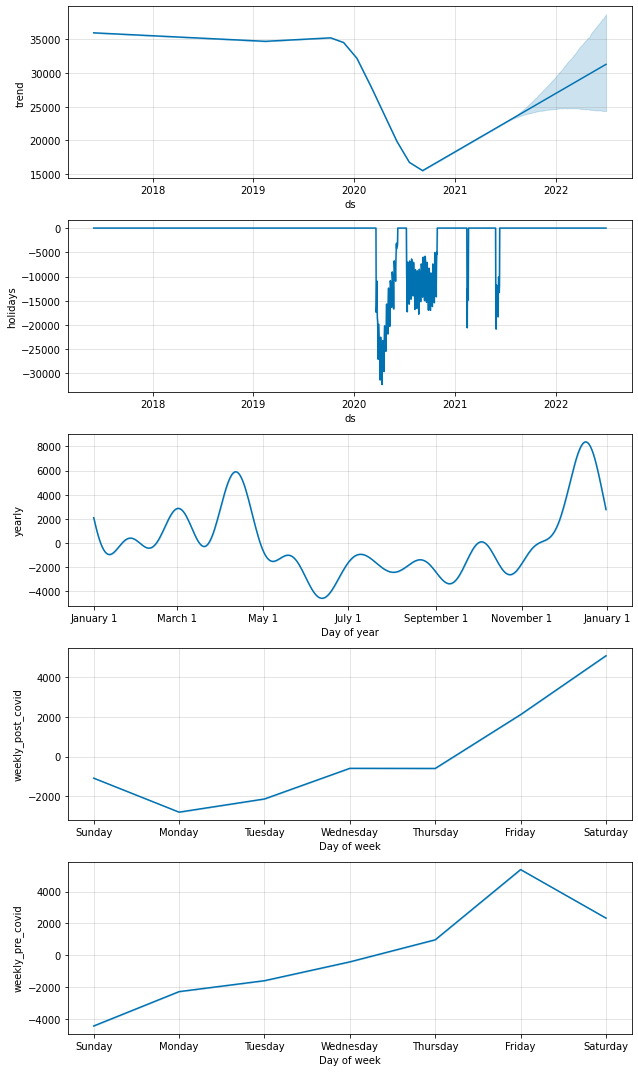
有趣的是,具有条件季节性的模型表明,在 COVID 之后,行人活动在周六达到高峰,而不是周五。 如果大多数人仍在在家工作,因此不太可能在周五晚上外出,这可能是合理的。 从预测的角度来看,只有当我们关心准确预测工作日与周末时,这才是重要的,但总的来说,这种探索有助于我们深入了解 COVID 如何改变行为。
进一步阅读
此页面上的许多内容都受到了此GitHub 讨论的启发。 我们已经介绍了一些在面对诸如 COVID 之类的冲击时调整 Prophet 模型的简单方法,但是还有许多其他可能的方法,例如
-
使用外部回归量(例如,封锁严格性指数)。 只有当我们 a) 拥有与我们正在预测的序列良好对齐(在位置方面)的回归量数据,并且 b) 对回归量的控制或预测比仅时间序列更准确得多时,这才是有效的。
-
检测并删除训练期间的异常值数据,或者完全丢弃较旧的训练数据。 对于没有年度季节性模式的子每日时间序列,这可能是一种更好的方法。
总的来说,在规则不断变化且疫情随机爆发的环境下,很难对我们的预测充满信心。在这种情况下,更重要的是不断地重新训练/重新评估我们的模型,并清楚地传达预测中增加的不确定性。
1
2
# Python